
Language models have gained significant traction in recent years due to their ability to process, generate, and manipulate texts in various human languages. However, despite their impressive capabilities, these models are not without flaws. One of the major challenges faced by large language models (LLMs) is the issue of hallucinations, where the model generates nonsensical or inaccurate responses. In a recent study by researchers at DeepMind, a novel approach was proposed to address this issue and improve the reliability of LLMs.
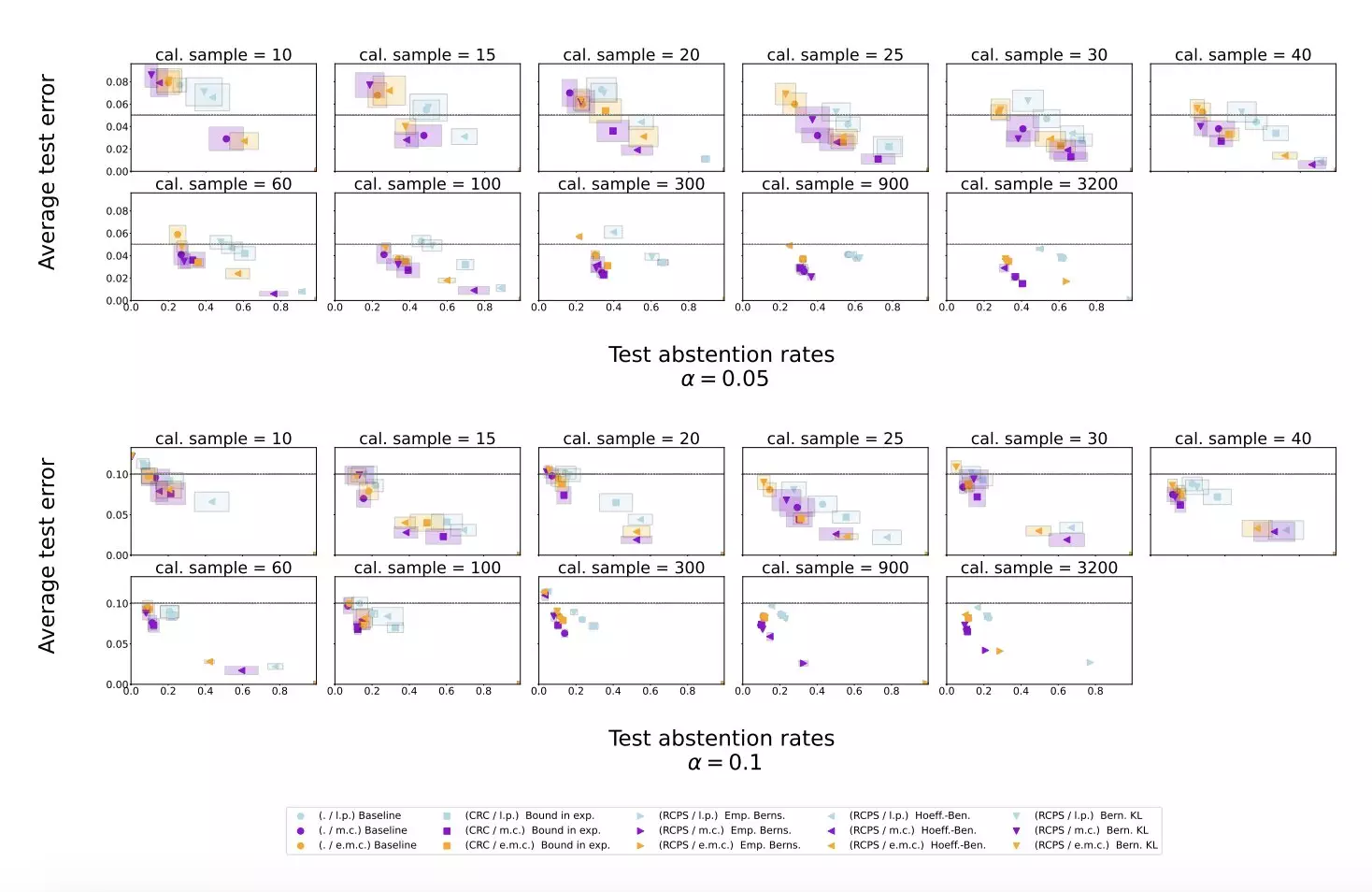
The research team at DeepMind introduced a new procedure that leverages LLMs to evaluate their own responses and identify instances where the model should abstain from providing an answer. By utilizing self-evaluation and conformal prediction techniques, the proposed method aims to reduce the likelihood of hallucinations occurring during text generation tasks. The team evaluated their approach using Temporal Sequences and TriviaQA datasets, demonstrating promising results in mitigating LLM hallucinations.
The experiments conducted by Yadkori, Kuzborskij, and colleagues showed that the conformal calibration and similarity scoring procedure effectively reduced hallucinations in LLMs. By implementing a more rigorous evaluation process, the model was able to abstain from providing incorrect or nonsensical responses, improving overall performance compared to baseline scoring procedures. The study highlights the potential of this approach to enhance the reliability of LLMs and pave the way for further developments in the field.
The findings of this study have significant implications for the future development of language models. By addressing the issue of hallucinations, researchers can improve the accuracy and trustworthiness of LLM-generated content. The proposed method by DeepMind sets a precedent for incorporating self-evaluation and conformal prediction techniques in LLM training, laying the foundation for more robust and reliable models in the future. As the technology continues to advance, efforts to mitigate hallucinations will be crucial in ensuring the widespread adoption of LLMs in professional settings worldwide.
The study conducted by DeepMind sheds light on the challenges faced by LLMs in generating accurate and coherent responses. By introducing a novel approach to identify and mitigate hallucinations, the research team has made significant strides in improving the reliability of language models. The results of the experiments demonstrate the effectiveness of the proposed method in reducing hallucination rates and enhancing the overall performance of LLMs. Moving forward, continued efforts to develop similar procedures will be essential in advancing the capabilities of language models and fostering their widespread use across various industries.
Leave a Reply