
The widespread application of large language models (LLMs) in conversational platforms like ChatGPT beckons the question of whether these models can craft responses so realistic that they rival human-generated content. A recent study conducted by researchers at UC San Diego tackled this inquiry head-on, employing a Turing test to evaluate the human-like intelligence of the GPT-4 model. The outcomes, disclosed in a pre-published paper on the arXiv server, revealed a striking resemblance between the GPT-4 model and human agents in 2-person conversations. This revelation raises concerns about the potential blurring of lines between human and AI-generated content.
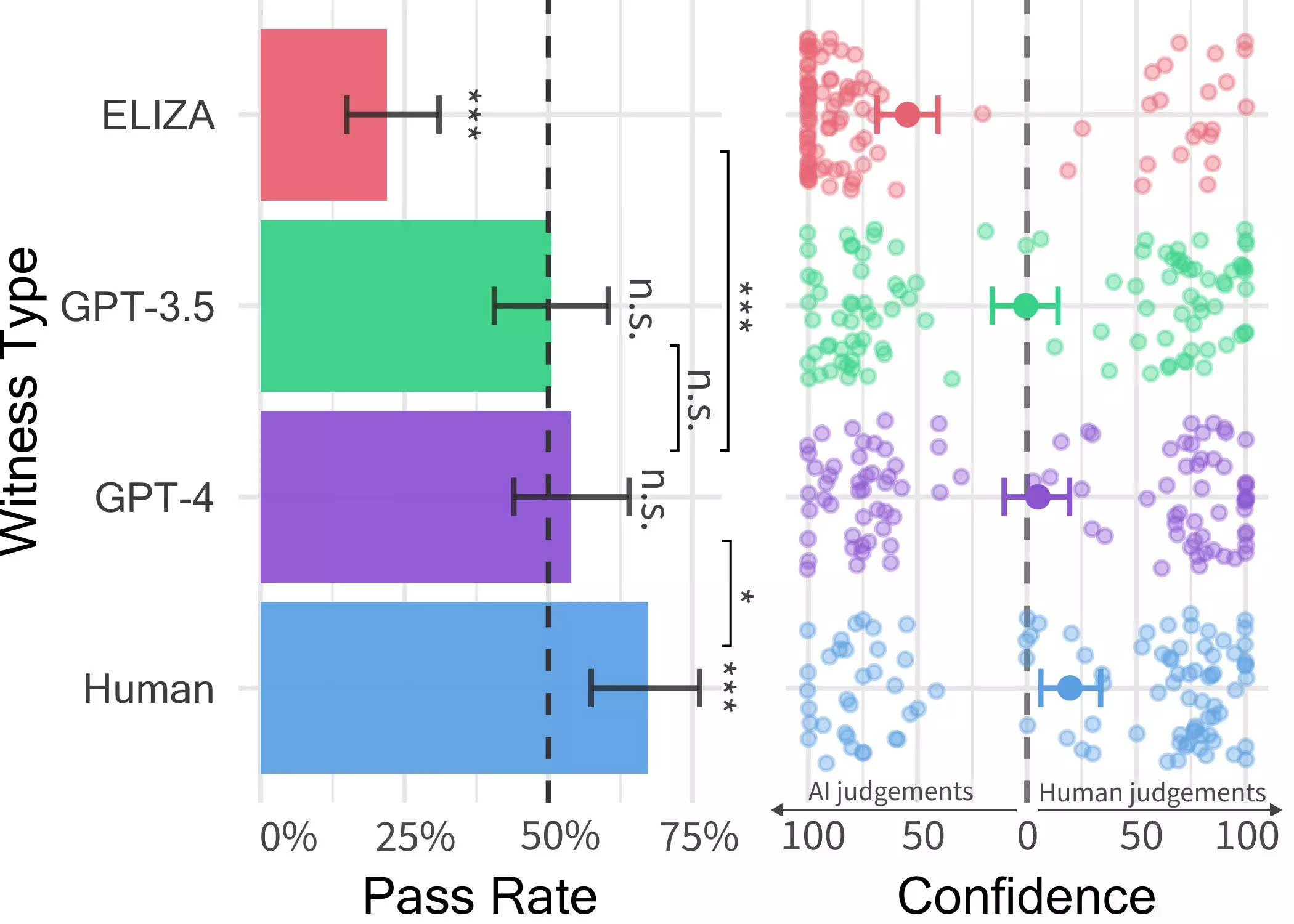
Initiated by Cameron Jones and overseen by Professor Bergen, the first experiment conducted to ascertain the human-likeness of GPT-4 elicited fascinating results, indicating that the model could pass as human in approximately half of the interactions. Despite this initial success, the presence of uncontrolled variables prompted the researchers to proceed with a follow-up experiment. The subsequent trial, outlined in their recent paper, delivered more nuanced insights into LLMs’ capacity to mimic human conversational patterns.
A key component of the researchers’ investigation was a two-player online game that pitted human participants against either another human or an AI model to discern their authenticity. Throughout the game, participants engaged in unrestricted conversations with witnesses, who were represented by three distinct LLMs: GPT-4, GPT 3.5, and ELIZA. The results underscored the difficulty users faced in distinguishing GPT-4 from human respondents, showcasing the model’s uncanny ability to emulate human interaction.
While real human respondents outperformed AI models in persuading interrogators of their humanity, the researchers’ findings suggest that the prevailing uncertainty in online interactions could intensify. The convergence of human-like responses from LLMs like GPT-4 with the prevalence of AI systems in various domains raises pertinent questions about the implications of this technology. As the line between human and machine communication blurs, the potential for deception and misinformation in online interactions escalates, necessitating a critical reevaluation of the role of AI in client-facing services and information dissemination.
The results of the Turing test administered by Jones and Bergen underscore the pressing need to reevaluate the authenticity of online interactions in light of increasingly sophisticated LLMs. With plans to expand their study to a three-person game setup, the researchers aim to delve deeper into the intricacies of human-machine communication. By investigating the nuances of interaction dynamics in a multiplayer setting, they hope to shed light on the evolving landscape of AI integration in daily interactions, offering valuable insights into the challenges and opportunities presented by the seamless integration of AI and human interaction.
Leave a Reply