
In the evolving domain of artificial intelligence, large language models (LLMs) have become pivotal in processing and generating human-like text. As these neural networks lay the groundwork for numerous applications—from chatbots to sophisticated data analysis tools—the need for effective customization approaches has emerged. Two prominent strategies have gained traction: fine-tuning and in-context learning (ICL). The intense rivalry between these methods highlights an essential inquiry for developers: which approach yields greater adaptability and generalization in real-world tasks?
A recent exploration by researchers from Google DeepMind and Stanford University scrutinizes this dilemma, revealing critical insights into how well each method equips models for unencountered tasks. Notably, ICL demonstrates superior generalization capabilities compared to traditional fine-tuning, albeit at a steeper computational cost during inference. This finding invites developers to weigh practical costs against potential performance benefits in their design of bespoke applications.
Defining Fine-Tuning and In-Context Learning
Fine-tuning involves enhancing a pre-trained LLM’s performance by training it further on a narrower dataset tailored to specific needs. This method modifies the model’s internal parameters to instill new knowledge and refined skills. Conversely, ICL skips the parametric adjustment route. Instead, it employs exemplary tasks directly inputted into the model’s prompt, allowing the environment to instruct the language model on how to execute specific queries based on provided examples.
The essence of fine-tuning lies in its adjustability; however, the model may become rigid as it’s shaped to fit a singular context. In contrast, ICL fosters a flexible approach by leveraging all available inputs, which can lead to impressive generalization capabilities. The research conducted by the two institutions robustly examined these approaches through controlled synthetic datasets, a methodology designed to rigorously test how models adapt when faced with completely novel information structures.
Innovative Methodologies Behind the Research
To thoroughly assess the generalization potential of these approaches, the researchers constructed synthetic datasets composed of fictitious yet intricately structured information such as imaginary family trees. Utilizing nonsensical terms devoid of overlap with previously encountered data further ensured that models relied on their learning capabilities.
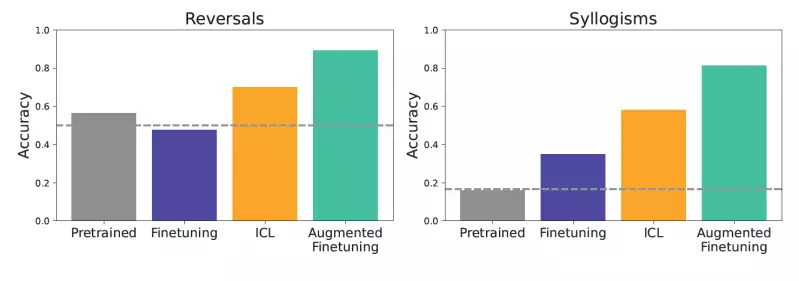
The experimental framework involved various scenarios, including simple reversals and syllogisms. For example, could a model infer from the statement “femp are more dangerous than glon” that “glon are less dangerous than femp”? Through methodical testing, it became evident that models trained through ICL consistently outperformed those merely fine-tuned.
The implications of this research are profound, particularly for enterprise applications where proprietary data is involved. As Andrew Lampinen, the lead author, points out, understanding how well models can generalize beyond their training data is paramount to ensuring robust performance in dynamic and specialized environments.
A New Frontier: Combining ICL and Fine-Tuning
Realizing the potential shortcomings of both methods, the researchers took a revolutionary step forward by proposing an augmented fine-tuning approach. This new methodology integrates ICL with fine-tuning, employing the language model’s own generation capabilities to create a richer and more diverse set of training examples.
This dual approach comprises two strategies: a local strategy that focuses on single pieces of data and a global strategy that utilizes the entire dataset for context. By introducing this enrichment phase before fine-tuning, models experience improved generalization capabilities, often surpassing the performance of models honed via traditional fine-tuning alone. Such innovation paves a path for enterprises aiming for more dependable and intelligent applications while mitigating the costs associated with extensive inference time.
The Trade-Offs and Future Considerations
Despite its promising advantages, it’s crucial to recognize the complexities that arise from augmented fine-tuning. While this method prevails in various scenarios, it inherently requires additional resources and time to implement. The cost-benefit analysis will vary depending on application-specific requirements, as developing augmented datasets demands both effort and investment. Yet, Lampinen’s insights suggest that the long-term sustainability of using augmented fine-tuning may overshadow its immediate computational expense by significantly enhancing future model interactions.
Beyond the practicalities of implementation, the implications of this research extend to broader inquiries about learning and generalization in foundational models. The findings encourage developers to probe deeper into how these methods can interrelate and adapt to emerging challenges in AI development, suggesting a vibrant area for future research.
As enterprises increasingly rely on LLMs for data-driven insights and customer engagement, navigating the complexities of training methodologies will define success. Embracing the innovations of augmented fine-tuning could very well become a cornerstone strategy in achieving superior performance across diverse real-world scenarios, transforming how organizations engage with artificial intelligence.
Leave a Reply